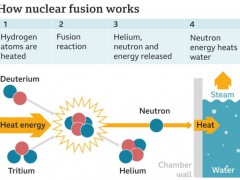
自然语言处理进入突破期
在人工智能领域,自然语言处理并不是最热门的领域。从市面上的投资分析来看,不论是投资金额还是公司数量,视觉识别和语音识别两个领域才是大头,自然语言处理了只占据了较小的一部分。不过姜大昕表示,在人工智能领域,都同意这样一个说法,即自然语言处理是人工智能皇冠上的明珠。一般认为,视觉和语音属于感知智能,自然语言处理属于感知智能之上的认知智能,不仅属于高级智能,也是通向真正人工智能的必由之路。

自然语言处理(NLP)的领域包括自然语言理解(NLU)、文本分析、搜索引擎、知识图谱、对话管理系统、推荐系统、基于知识库的问答系统、基于搜索的问答系统等,可广泛应用在机器翻译、广告、人机交互、金融、客服、物流等领域。由于自然语言处理对于认知智能的重要性,学术界和工业界对于自然语言处理技术的追求就没有停止过。
其中,有影响力的工作包括2003年Yoshua Bengio提出的一个神经网络语言模型,他也是2018图灵奖获得者、“深度学习三巨头”之一,但这个模型训练起来比较慢,所以并没有流行起来。十年后的2013年,Mikolov发明了词向量模型,极大简化和加速了Bengio模型,该模型非常简单且在实践中的效果非常好,虽然并不算是深度学习模型,但在当时成为了自然语言处理的一个标配。接下来的几年,自然语言处理一直在借鉴视觉识别和语音识别领域的重大突破性技术,比如循环神经网络、卷积神经网络、残差网络、生成对抗网络等等,这些技术起源于视觉和语音,但都被成功地移植到了自然语言处理领域。
针对语言自身的特点,自然语言处理领域也创新了一些独有技术来处理文字,例如序列到序列模型、注意力机制以及Transformer,近期像Transformer技术甚至反哺回了视觉识别和语音识别领域。但对于自然语言处理领域而言,至少在2017年的时候,颠覆性革命似乎还没有到来。
在视觉识别和语音识别领域,2015年和2017年是一个分水岭。2015年,微软亚洲研究院孙健博士所在的团队创造了一个深达152层的残差网络ResNet,在世界公认的图像识别数据集ImageNet上,将图像识别的错误率降低到了3.57%,而人类的错误率大概是5.1%。换句话说,在图像识别领域,2015年的时候,人工智能已经获得了超越人类的水平。到了2017年,语音识别领域也取得了历史性的成果——在全球最权威的产业标准 Switchboard语音识别数据集上,微软语音识别系统将错误率降低到了5.1%,首次比人类的错误率还要低。这是人工智能第一次在语音识别领域达到人类的水平,同时也标志着人工智能在语音领域取得了重大的突破。
当视觉识别和语音识别先后达到人类水平以后,自然语言处理是不是也能够取得类似的重大突破?能够在一些代表性的任务上也达到人类的水平?2018年底,一个叫做BERT的模型出世,横扫NLP任务各大榜单,比如在斯坦福著名的阅读理解测试集上超越了人类的准确率。